" 빅데이터 분석 프로젝트(1) " - 데이터 정제, 변수추출
2022. 8. 22. 17:18ㆍ빅데이터 분석 프로젝트
주제 : 부산시 수소충전소 최적입지 선정
개요 : 수소차 이용자들의 접근성, 효율성을 고려한 수소충전소 최적 입지분석 및 정부의 정책의도 반영
▶ 데이터 분석 과정
- 분석프로세스 정립
- 전국 단위 데이터 수집
- 수집한 데이터 정제
- 데이터 정제 후 주요 변수 추출
▶ 데이터 분석프로세스

▶ 데이터 수집 ( 공공데이터 위주로 파악하고 필요에 따라 민간데이터도 수집)
| 구분 | 활용 데이터 |
기간 | 제공기관 |
현황 데이터 |
수소충전소 현황 | 2022 | - 통계는 일단위 집계, 현황은 실시간 수집/서비스되고 있음 환경부(무공해차 통합누리집) |
| 부산 법정동별 자동차 등록현황 | 2022 | - 공공데이터포털 | |
| 수소충전소 설치기준 | 2021 | - 환경부 (수소충전소 구축 운영 매뉴얼) |
|
| 전국 표준지공시지가 | 2022 | 공공데이터포털 | |
위치 적합성 |
전국 공영 차고지 | 2021 | - 국가 물류 통합정보센터 |
| 전국 주유소 위치 현황 | 2022 | - 국토 교통부 주유소 위치 데이터 Opinet - 국토지리정보원 연속수치 지형도 주유소 공간 SHP 데이터 |
|
| 전국 도시공원 위치 현황 | 2022 | 공공데이터포털 | |
| 전국 주차장 위치 현황 | 2022 | - 국토지리정보원 연속수치 지형도 | |
| 인구 특성 |
지역별 총생산량 | 2022 | - KOSIS 국가통계포털 |
| 총생산인구 | 2022 | - 국토교통부 국토지리정보원 ngii map |
|
| 총인구수 | 2021 | - 국토교통부 국토지리정보원 ngii map |
|
| 민간 데이터 |
전국 시군구 | SHP | 공간정보시스템 / 딥러닝 기반 기술 연구소 |
| 부산 시군구 | SHP | 공간정보시스템 / 딥러닝 기반 기술 연구소 |
▶ 데이터 정제
● 데이터 정제 과정
- Geo - Coding
- 필요한 데이터 칼럼 추출 및 삭제
- 데이터 실수화
- 중복값 및 결측값 처리
- 데이터 병합 (카운트, 평균, 합계)
● 데이터 정제 일부 예시 코드
# 전국 공시지가 데이터 정제
# 패키지 임포트
import pandas as pd
import numpy as np
# 수집한 데이터 파일 로드
df = pd.read_csv("./국토교통부_표준지공시지가_20220527.csv", encoding = 'utf-8', engine = 'python')
df
# 불필요한 칼럼 삭제 및 리인덱스
df1 = df[df['시도명'].str.contains('제주특별자치도')].index
df.drop(df1, inplace=True)
df
df.reset_index(drop=True, inplace=True)
df
# 필요한 칼럼만 추출
표준지공시지가_df = df[['시군구', '시도명', '시군구명', '이용상황', '공시지가']]
표준지공시지가_df
# 정제한 데이터 병합 (평균값)
시군구_groupby = 표준지공시지가_df.groupby('시군구').mean()
시군구_groupby
# 병합한 데이터 csv로 저장
dff.to_csv("시군구_토시지가_평균.csv", index = False, encoding = 'cp949')▶ 변수 추출 ( 상관관계분석 및 변수 중요도, PCA분석 )
● 상관관계 분석
# 상관관계 분석
# 필요 패키지 임포트
import pandas as pd
import warnings
warnings.simplefilter(action = 'ignore', category = FutureWarning)
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import os
# 깨짐 방지를 위한 Font 지정
import os
if os.name =='nt' :
font_family = "Malgun Gothic"
else :
font_family = "AppleGothic"
# 값이 깨지는 문제 해결을 위해 파라미터값 설정
sns.set(font=font_family, rc = {"axes.unicode_minus" : False})
gg = pd.read_CSV('./전처리데이터_수정.CSV', encoding = "euc-kr")
cor = pd.DataFrame(gg)
cor.head()
cor.info()
del cor['Unnamed: 0']
del cor['Unnamed: 0.1']
del cor['Unnamed: 0.2']
cor
Hyd = pd.read_CSV('./전국시군구_수소충전소개수.CSV', encoding = "euc-kr")
Hyd_df = pd.DataFrame(Hyd)
Hyd_df.head()
cor = pd.merge(cor, Hyd_df, on = '시군구코드', how = 'left')
cor
del cor['시군구코드']
cor
cor.info()
cor.fillna(0)
cor
del cor['충전소']
del cor['시군구']
cor
cor.to_CSV("분석용데이터_상관계수.CSV", encoding = "EUC-KR")
cor.info()
# 상관계수 분석
co = cor.corr()
co
sns.heatmap(co, annot = True, cmap = plt.cm.Blues)
plt.show()
# 시각화
sns.pairplot(co, diag_kind = 'hist')
plt.show()
# 상관계수 점검
import scipy.stats as sp
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['총생산'])
print("총생산")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['총생산인구수'])
print('')
print("총생산인구수")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
print('')
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['총인구수'])
print("총인구수")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
print("")
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['공시지가'])
print("공시지가")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
print('')
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['차고지개수'])
print("차고지개수")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
print('')
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['주차장개수'])
print("주차장개수")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
print('')
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['도시공원_개수'])
print("도시공원_개수")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['총생산'])
print('')
print("총생산")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
corr_values, pval = sp.pearsonr(cor['수소충전소개수'], cor['주유소개수'])
print('')
print("주유소_개수")
print("총생산")
print('상관계수 : ', corr_values)
print('p_value : ', format(pval, '.55f'))
● 변수 중요도 파악 (랜덤 포레스트 기반)
import pandas as pd
import warnings
warnings.simplefilter(action = 'ignore', category = FutureWarning)
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import os
# 깨짐 방지를 위한 Font 지정
import os
if os.name =='nt' :
font_family = "Malgun Gothic"
else :
font_family = "AppleGothic"
""
# 값이 깨지는 문제 해결을 위해 파라미터값 설정
sns.set(font=font_family, rc = {"axes.unicode_minus" : False})
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np # 벡터, 행렬 등 수치 연산을 수행하는 선형대수 라이브러리
import pandas as pd # 시리즈, 데이터프레임 포맷 데이터 처리를 위한 라이브러리
import warnings; warnings.filterwarnings(action='ignore') # 경고 메시지 무시
import matplotlib.pyplot as plt # 데이터 시각화 라이브러리
import pickle # 객체 입출력을 위한 라이브러리
from sklearn.model_selection import train_test_split # 훈련 데이터, 테스트 데이터 분리
from sklearn.preprocessing import StandardScaler # 정규화
from sklearn.ensemble import RandomForestClassifier as RFC # 랜덤포레스트 분류 알고리즘
from sklearn.tree import DecisionTreeClassifier as DTC # 의사결정나무 분류 알고리즘
from sklearn.ensemble import GradientBoostingClassifier as GBC # 그래디언트 부스팅 분류 알고리즘
# 모델 평가를 위한 metrics
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, plot_confusion_matrix
gg = pd.read_CSV('C:/Users/user/공공빅데이터_프로젝트/전처리데이터/전처리데이터_최종.CSV', encoding = "euc-kr")
cor = pd.DataFrame(gg)
cor.head()
del cor['Unnamed: 0']
del cor['Unnamed: 0.1']
del cor['Unnamed: 0.2']
cor
Hyd = pd.read_CSV('C:/Users/user/공공빅데이터_프로젝트/전국시군구데이터_전처리용/전국시군구_수소충전소개수.CSV', encoding = "euc-kr")
Hyd_df = pd.DataFrame(Hyd)
Hyd_df.head()
cor = pd.merge(cor, Hyd_df, on = '시군구코드', how = 'left')
cor
del cor['시군구코드']
del cor['충전소']
del cor['시군구']
cor.fillna(0)
cor.info()
cor.target = cor['수소충전소개수']
print(cor.shape)
cor.head()
# 각 변수 p-value 0.05 미만 제거
# 변수 선택
feature_columns = list(cor.columns.difference(['수소충전소개수']))
# 변수 확정
X = cor[feature_columns] # 설명변수
## 스케일링 & 정규화
scaler = StandardScaler()
scaler.fit(X)
X_std = scaler.transform(X)
## 데이터 생성
X_train_b, X_test_b, y_train_b, y_test_b = train_test_split(X_std,
cor.target,
test_size = 0.2,
random_state = 20)
feature_columns
X_train_b[0]
from sklearn.ensemble import RandomForestRegressor
from math import sqrt
from sklearn.metrics import mean_squared_error
rf_refressor = RandomForestRegressor(random_state = 5,
max_depth = 2,
min_samples_split = 8,
n_estimators = 10)
rf_refressor.fit(X_train_b, y_train_b)
## 성능평가
# R2 Score
print("R2 Socre:", rf_refressor.score(X_train_b, y_train_b, sample_weight = None))
# train rmse
train_predict = rf_refressor.predict(X_train_b)
print("train RMSE : {}".format(sqrt(mean_squared_error(train_predict,y_train_b)))) # RMSE 결과
# test rmse
test_predict = rf_refressor.predict(X_test_b)
print("test RMSE : {}".format(sqrt(mean_squared_error(test_predict,y_test_b))))
# 하이퍼 파라미터 조정
from sklearn.ensemble import RandomForestRegressor
from math import sqrt
from sklearn.metrics import mean_squared_error
rf_refressor = RandomForestRegressor(random_state = 5,
max_depth = 7,
min_samples_split = 8,
n_estimators = 100)
rf_refressor.fit(X_train_b, y_train_b)
## 성능평가
# R2 Score
print("R2 Socre:", rf_refressor.score(X_train_b, y_train_b, sample_weight = None))
# train rmse
train_predict = rf_refressor.predict(X_train_b)
print("train RMSE : {}".format(sqrt(mean_squared_error(train_predict,y_train_b)))) # RMSE 결과
# test rmse
test_predict = rf_refressor.predict(X_test_b)
print("test RMSE : {}".format(sqrt(mean_squared_error(test_predict,y_test_b))))
## 변수 중요도 시각화
ftr_importances_value = rf_refressor.feature_importances_
ftr_importances = pd.Series(ftr_importances_value, index = feature_columns)
ftr_top = ftr_importances.sort_values(ascending = False)
plt.figure(figsize = (8,6))
sns.barplot(x = ftr_top, y= ftr_top.index)
plt.show()
# 정확도 측정
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train_b,y_train_b)
pred = rf_clf.predict(X_test_b)
accuracy = accuracy_score(y_test_b, pred)
print('랜덤 포레스트 정확도: {:.4f}'.format(accuracy)) |
 |
- 상관관계 분석 및 변수중요도 파악 시각화 -
● PCA 차원축소 ( 정규화 후 진행 )
# PCA 차원축소
import plotly.express as px
from sklearn.decomposition import PCA
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
features = ['총생산', '총생산인구수', '수소차대수', '주차장개수', '도시공원_개수', '주유소개수']
X = bs_scaled_df[features]
pca = PCA(n_components=2)
components = pca.fit_transform(X)
loadings = pca.components_.T * np.sqrt(pca.explained_variance_)
fig = px.scatter(components, x=0, y=1)
for i, feature in enumerate(features):
fig.add_shape(
type='line',
x0=0, y0=0,
x1=loadings[i, 0],
y1=loadings[i, 1]
)
fig.add_annotation(
x=loadings[i, 0],
y=loadings[i, 1],
ax=0, ay=0,
xanchor="center",
yanchor="bottom",
text=feature,
)
fig.show()
# 데이터가 어느정도를 반영하는 지 점검
pca = PCA(random_state=1107)
X_p = pca.fit_transform(bs_scaled_df)
pd.Series(np.cumsum(pca.explained_variance_ratio_))
# 2개일때도 괜찮으므로 2개 하자.
# PCA 주성분 비율확인
percent_variance = np.round(pca.explained_variance_ratio_* 100, decimals =2)
columns = []
for i in range(len(percent_variance)):
columns.append(f'PC{i+1}')
ax = plt.bar(x = range(len(percent_variance)), height=percent_variance, tick_label=columns)
plt.ylabel('Percentate of Variance Explained')
plt.xlabel('Principal Component')
plt.title('PCA Scree Plot')
plt.show()
pca_columns = ['pca_components_1', 'pca_components_2']
bs_pca_df = pd.DataFrame(bs_pca, columns = pca_columns)
bs_pca_df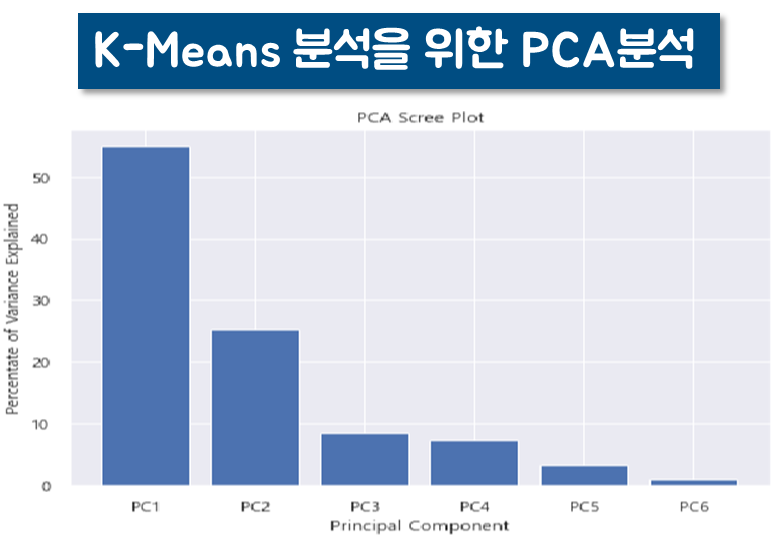
데이터 수집부터 변수 추출까지의 데이터 분석 과정입니다.
다음 포스팅 때에는 군집분석부터 최종입지선정까지 올리겠습니다.
'빅데이터 분석 프로젝트' 카테고리의 다른 글
| "빅데이터 분석 프로젝트" - 거주자우선주차구역 부정주차 해소 (0) | 2022.11.01 |
|---|---|
| " 빅데이터 분석 프로젝트(2) " - 데이터 분석, 결과 시각화 (0) | 2022.08.24 |