" 빅데이터 분석 프로젝트(2) " - 데이터 분석, 결과 시각화
2022. 8. 24. 17:46ㆍ빅데이터 분석 프로젝트
주제 : 부산시 수소충전소 최적입지 선정
개요 : 수소차 이용자들의 접근성, 효율성을 고려한 수소충전소 최적 입지분석 및 정부의 정책의도 반영
▶ 데이터 분석 과정
- 주요 변수들을 이용한 군집분석
- 최적 군집 선정
- 선정된 행정구에 대한 Qgis 격자 생성
- 선정한 군집의 변수들에 대한 가점셋 설정 및 순위 선정
- 순위에 따른 Folium 지도 맵핑
- Qgis 결과 시각화 및 최종 입지 선정
▶ 군집분석 ( 계층적 군집 & 비계층적 군집 )
● 계층적 군집분석 ( Hierarchical Clustering )
=> 계층적 군집분석은 주요 변수 추출 과정에서 초기 군집개수를 설정하기 위해 사용
# 계층적 군집분석
# 필요 라이브러리 임포트
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
sns.set_palette("hls")
import warnings
warnings.filterwarnings('ignore')
# 값이 깨지는 문제 해결을 위해 파라미터값 설정
import os
if os.name == 'nt' : # windows OS
font_family = "Malgun Gothic"
else : #Mac OS
font_family = "AppleGothic"
sns.set(font=font_family, rc ={"axes.unicode_minus" : False})
# 전처리 데이터 불러오기
busan_df = pd.read_CSV('C:/Users/user/공공빅데이터_프로젝트/전처리데이터/부산전처리.CSV', encoding = "EUC-KR")
busan_df
# 불필요한 칼럼, 다중공선성을 가졌던 칼럼 삭제
del busan_df['시군구명']
del busan_df['시군구코드']
del busan_df['총인구수']
busan_df
# 계층적 군집분석
from scipy.cluster.hierarchy import linkage, dendrogram
linkage_list = ['single', 'complete', 'average', 'centroid', 'ward']
data = [busan_df, bs_scaled_df]
fig, axes = plt.subplots(nrows=len(linkage_list), ncols=2, figsize=(16, 35))
for i in range(len(linkage_list)):
for j in range(len(data)):
hierarchical_single = linkage(data[j], method=linkage_list[i])
dn = dendrogram(hierarchical_single, ax=axes[i][j])
axes[i][j].title.set_text(linkage_list[i])
plt.show() # 분석 결과 Ward 기법이 가장 적정한 군집 형성 K = 4
● 비계층적 군집분석 ( K-means 분석 ), R 군집분석
=> 6개의 변수를 2차원으로 차원축소하여 군집분석 진행, 파이썬과 R 두가지 툴을 이용하여 비교, K = 4로 확정
# Python 군집 결과
# K-means 군집분석
from sklearn.cluster import KMeans
k = 4
# 그룹 수, random_state 설정
model = KMeans(n_clusters = k, random_state = 5)
# 정규화된 데이터에 학습
model.fit(bs_pca_df)
# 클러스터링 결과 각 데이터가 몇 번째 그룹에 속하는지 저장
bs_pca_df['cluster'] = model.fit_predict(bs_pca_df)
bs_pca_df
# 시각화
import matplotlib.pyplot as plt
plt.figure(figsize = (8, 8))
for i in range(k):
plt.scatter(bs_pca_df.loc[bs_pca_df['cluster'] == i, 'pca_components_1'],
bs_pca_df.loc[bs_pca_df['cluster'] == i, 'pca_components_2'],
label = 'cluster ' + str(i))
plt.legend()
plt.title('K = %d results'%k , size = 15)
plt.xlabel('pca_components_1', size = 12)
plt.ylabel('pca_components_2', size = 12)
plt.show()# 데이터 가져오기
busandata <- read.CSV('부산_전처리.CSV',header=TRUE,fileEncoding = 'euc-kr',encoding='utf-8')
rownames(busandata)<-c(busandata$시군구명)
busandata %<>% select(-시군구명)
# 클러스터링
# standardization (scaling)
busandata %>% head()
busan_scaled <- data.frame(scale(busandata))
head(busan_scaled)
set.seed(1234)
kmeans_k4 <- kmeans(busan_scaled, centers = 4)
names(kmeans_k4)
kmeans_k4$centers
busandata$cluster <- kmeans_k4$cluster
busandata %>%
group_by(cluster) %>%
summarise(총생산 = mean(총생산),
수소차대수 = mean(수소차대수),
총인구수 = mean(총인구수),
주차장개수 = mean(주차장개수),
도시공원_개수 = mean(도시공원_개수),
주유소개수 = mean(주유소개수))
## Parallel Coordinates Plot 평행좌표
library(GGally)
busandata$cluster <- as.factor(busandata$cluster)
kmeansplot <- ggparcoord(data = busandata,
columns = c(1:6),
groupColumn = "cluster",
scale = "std") +
labs(x = "부산광역시 수소충전소 입지 분석 요소",
y = "value in scaled",
title = "Parallel Coordinates Plot by Cluster")+theme_bw()
kmeansplot
## Interactive plot using ggplotly 군집별 평행 좌표 그림
library(plotly)
ggplotly(kmeansplot)
## fviz_silhouette:Visualize Silhouette Information from Clustering 클러스터링에서 실루엣 정보 시각화
library(factoextra)
fviz_cluster(kmeans_k4, busan_scaled, ellipse.type = "norm")+
theme_minimal()=> 군집분석 결과 파이썬과 R 결과가 거의 유사하게 도출됨.
=> 4개의 군집 중 주성분이 잘 나타난 군집을 선정 (1번 클러스터와, 4번 클러스터 선정)
=> 군집으로 묶인 행정구 중 이미 충전소가 있는 지역은 제외하여 최종적으로 부산진구, 사하구 선정
● 선정된 행정구 Qgis 격자 생성
=> 부산진구와 사하구에 대한 격자를 생성 후 주요 변수들의 개수를 격자에 속성 결합
 |
 |
● 선정한 군집의 변수들에 대한 가점셋 설정 및 순위 선정
# 총점 및 등수 계산
# 필요 라이브러리 임포트
import pandas as pd
import numpy as np
# 데이터 불러오기
df = pd.read_CSV('C:/Users/user/공공빅데이터_프로젝트/최적입지분석용데이터_최종.CSV', encoding = 'cp949')
df
# 칼럼확인
all_columns = df.columns.tolist()
all_columns
점수칼럼 = ['주유소개수', '주차장개수','도시공원개수']
print("점수칼럼명\n", 점수칼럼)
# 가중치선언
가중치 = [5,1,2]
if (len(가중치) != len(점수칼럼)):
print("입력한 가중치 갯수가 점수칼럼 갯수와 다르므로 확인후 다시 입력 바랍니다")
else:
print("다음 줄을 실행 하세요“)
df.fillna(0, inplace=True)
df
df.sort_values('주유소개수', ascending = True)
df
df.info()
# 총점계산
total_score = df.copy()
for i in range(0, len(점수칼럼)):
name = 점수칼럼[i]
df[name] = df[name] * 가중치[i]
df.set_index(['id','lon','lat'], inplace=True)
df['sum'] = df.sum(1)
df.reset_index(inplace=True)
# 등수 계산
df['순위'] = df['sum'].rank(method='dense', ascending=False).astype(int)
final = df.sort_values(by='순위')
final.reset_index(drop=True, inplace=True)
# 상위 20개만 학인
display("결과", final.head(20))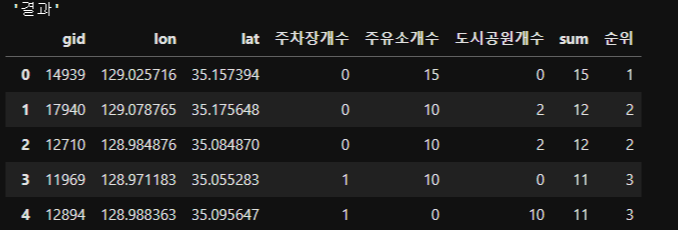
● 순위에 따른 Folium 지도 맵핑
# folium을 이용하여 지도로 시각화
지도보기갯수 = 5
! pip install folium
import folium
print(f"보고자 하는 상위권 갯수는 {지도보기갯수}개 입니다.")
for i in range(지도보기갯수):
지도보기 = folium.Map(location=[final.loc[i,'lat'],final.loc[i,'lon']], zoom_start = 15)
folium.Marker([final.loc[i,'lat'],final.loc[i,'lon']]).add_to(지도보기)
print (final.loc[i,'lat'],final.loc[i,'lon'])
j = i+1
display(f'상위 {j}번째 격자의 센터 위치 보기', 지도보기)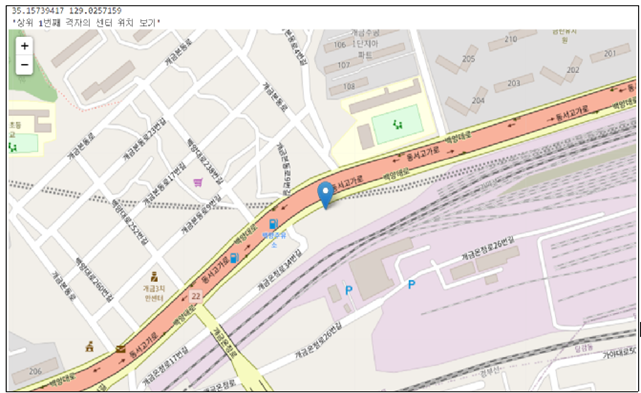
● Qgis 결과 시각화 및 최종 입지 선정
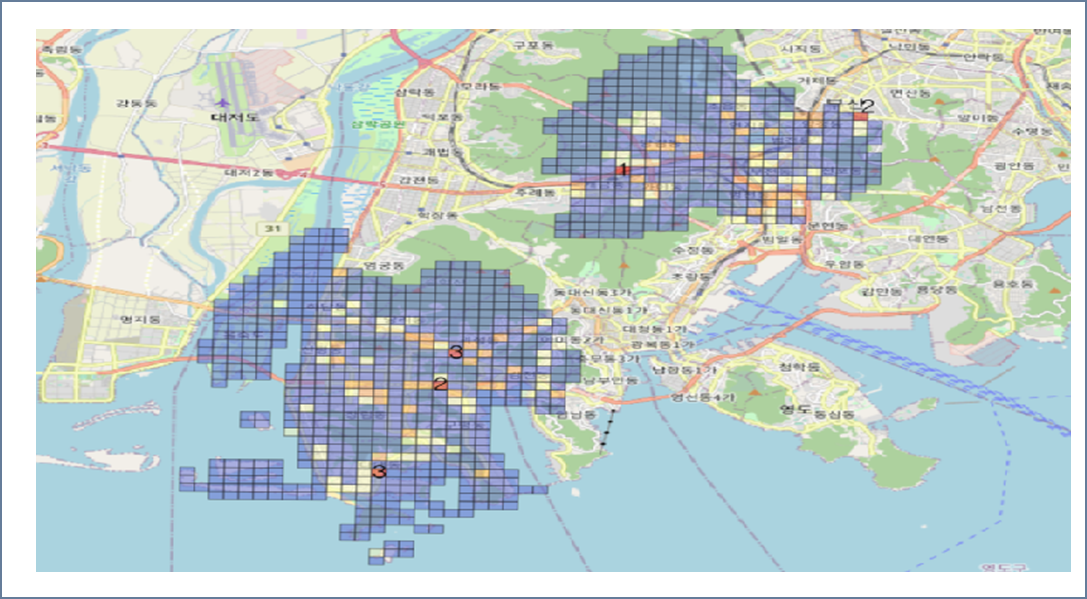
=> Qgis 분류값 사용과 버퍼 생성으로 순위를 나타낸 격자 시각화

지금까지 데이터 분석 프로젝트 과정에 대해 나열해보았습니다.
중간중간 생략된 부분들이 많지만 분석을 할 때 가장 중요한 부분은 데이터 수집과 실현 가능성인듯 합니다.
다음에 프로젝트는 더 현실성 있는 데이터 분석으로 포스팅 하겠습니다. 감사합니다~
'빅데이터 분석 프로젝트' 카테고리의 다른 글
| "빅데이터 분석 프로젝트" - 거주자우선주차구역 부정주차 해소 (0) | 2022.11.01 |
|---|---|
| " 빅데이터 분석 프로젝트(1) " - 데이터 정제, 변수추출 (2) | 2022.08.22 |